Databricks SQL, a serverless SQL warehouse, was introduced four years ago as a first-class citizen within the Databricks ecosystem, integrated into the same data management that underpins Databricks Clusters, Unity Catalog, and related tooling.
At the 2024 Databricks AI Summit in June, Databricks hosted a session on migrating data from Snowflake to Databricks SQL. The talk included a brief segment featuring code snippets that utilized AWS as the cloud transfer intermediary.
This blog outlines all the necessary steps and utilizes Azure ADLS as the cloud handoff. All the code is included in a Databricks Jupyter Notebook, which is available for download at the end of this blog.
The Data to Migrate
Our work in complex data solutions provides access to diverse data environments, one being an anonymized dataset of 4.75 million clinical diagnoses that we used to develop disease forecasting algorithms stored in Snowflake. We will migrate the entire dataset to Databricks, reproducing the schema and stored values.
The migration process has one goal: to reproduce data accurately. This involves adjusting for data type and format differences while maintaining the integrity of existing data rules.
The Method
A SQL programmer might address data conversion by developing go-between migration logic: reading the source data via the Snowflake SQL client, adapting the data to the universal ANSI standard, and then writing the result to Databricks using the Databricks SQL client.
However, we can use an internal conversion method that leverages Parquet, a highly efficient and flexible open data store format supported by major data platforms.
When a Snowflake table is exported to Parquet, its native data types are converted to Parquet’s simpler structure with additional complexity expressed as metadata. When imported to Databricks, the process is reversed.
We’ll use ADLS to hold the Parquet intermediary objects, provisioned in the same region as our Snowflake and Databricks tenants, for speed and reduced egress charges.
This approach is orders of magnitude faster and cheaper than using a database-to-database connection. We can transfer tables with hundreds to billions of rows, bypassing the need for complex and computationally expensive conversion pipelines benefiting from Parquet as the data go-between.
Understanding Data Type Peculiarities
All database platforms have their data type peculiarities. To understand how this will impact our data migration, we ask our friendly large language model (LLM).
With products changing so fast, it’s a game-changer to have an LLM instantly point you in the “right” direction, so long as you intelligently sniff-test everything it pronounces.
In the Databricks ecosystem, the Databricks Assistant is always there, tucked away in the margin. Like everything in LLM land, it feels like a version 1 product: genuinely helpful but prone to going wayward. I’ll call it DA for short.
Let’s use DA to get a take on how Databricks SQL supports ANSI standard data types…
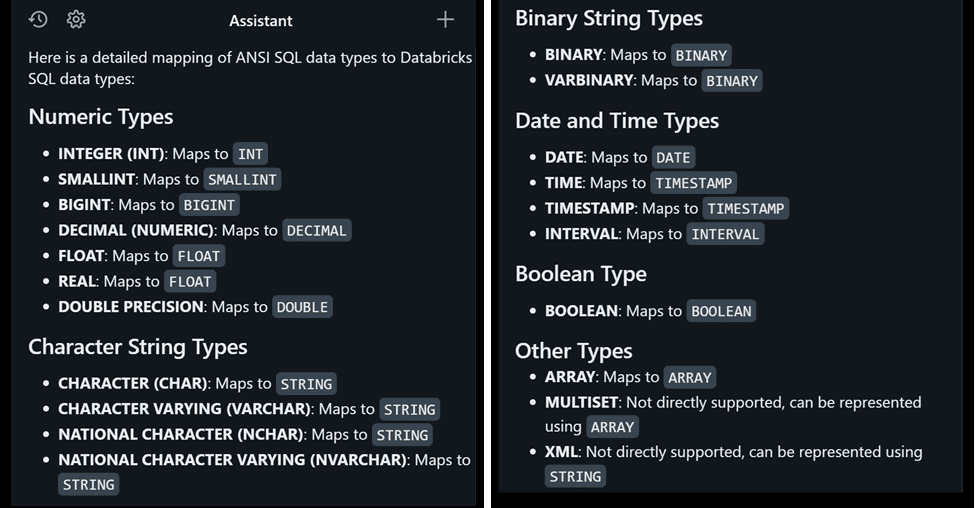
A key difference is all character fields map to the STRING type; therefore, the character limit enforcement of VARCHAR(n) is lost and must be handled in logic if required. We can see this behavior with the ADMISSIONS table before and after migration…
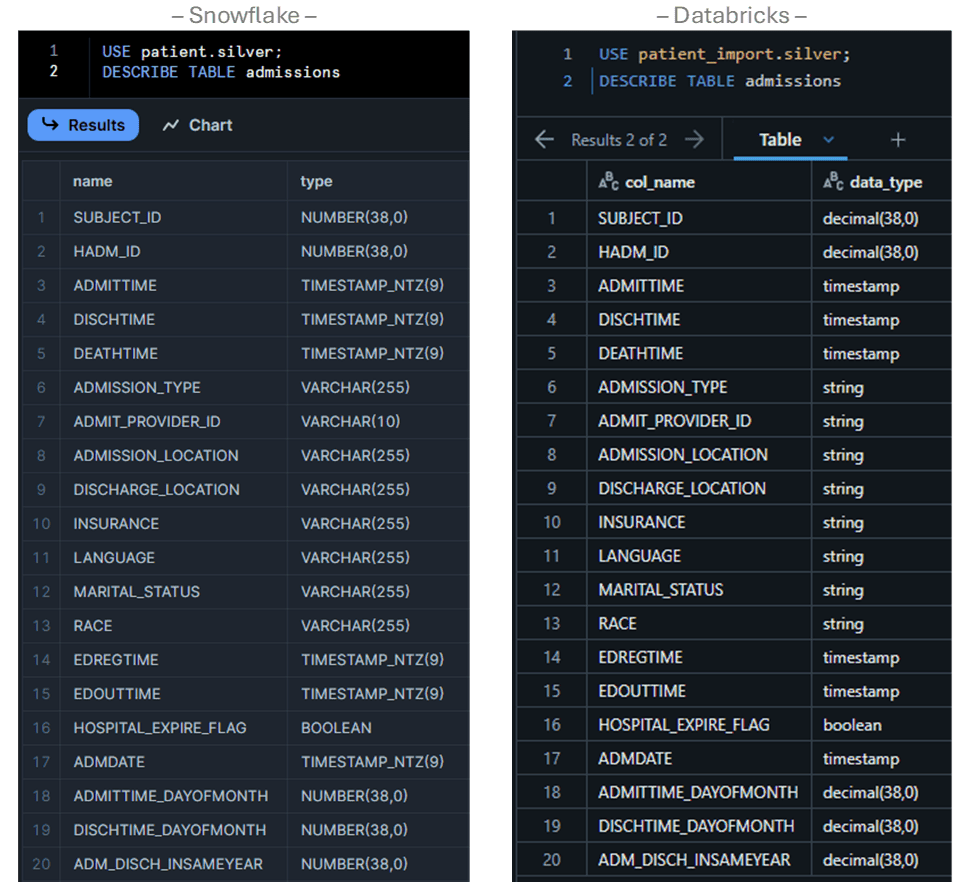
Also, note Snowflake’s use of TIMESTAMP_NTZ has been converted to the ANSI-standard TIMESTAMP.
Step 1 – Preparation
We provision a minima l Databricks Cluster to run the Python code that will control the process… l Databricks Cluster to run the Python code that will control the process… |
We need an ADLS storage container with a shared access signature (SAS) token that the Python Notebook will use. It’s more interesting to see the container populated with the exported tables in the screenshot below, but it will be empty until later steps are completed…
We’ll use the Databricks Secrets vault to store and retrieve sensitive credentials. We set up the secrets by opening the cluster terminal and using the CLI…

The Databricks Notebook is “secrets aware” and will display “redacted” for variables assigned a Secret. We load the secrets into a Python dictionary for convenience…
… And use them to create the connection parameters for Snowflake, Databricks, and ADLS…
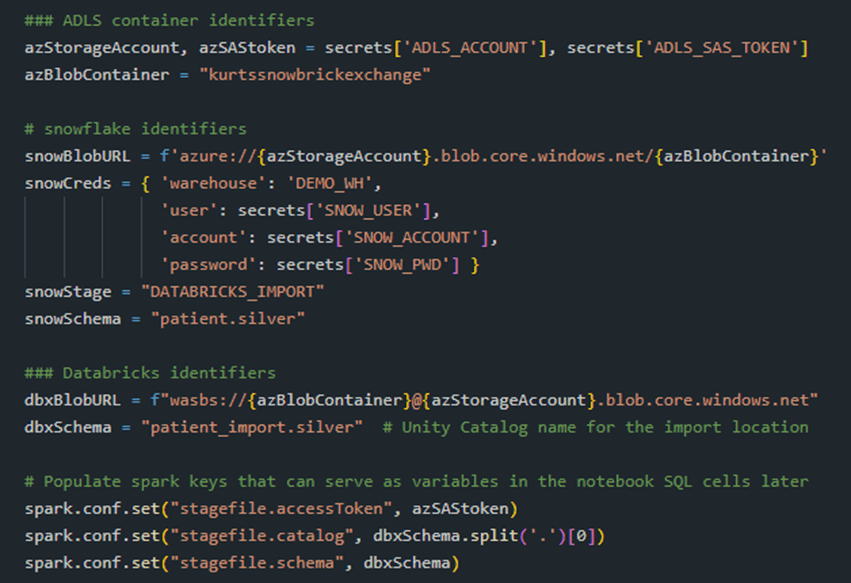
We create a convenience function, snow_exec(), that wraps the Snowflake Python library to return a dictionary of column names with row values. We won’t use it to retrieve business data; that would be lousy; rather, we use it to initiate the Parquet processes, as you will see.
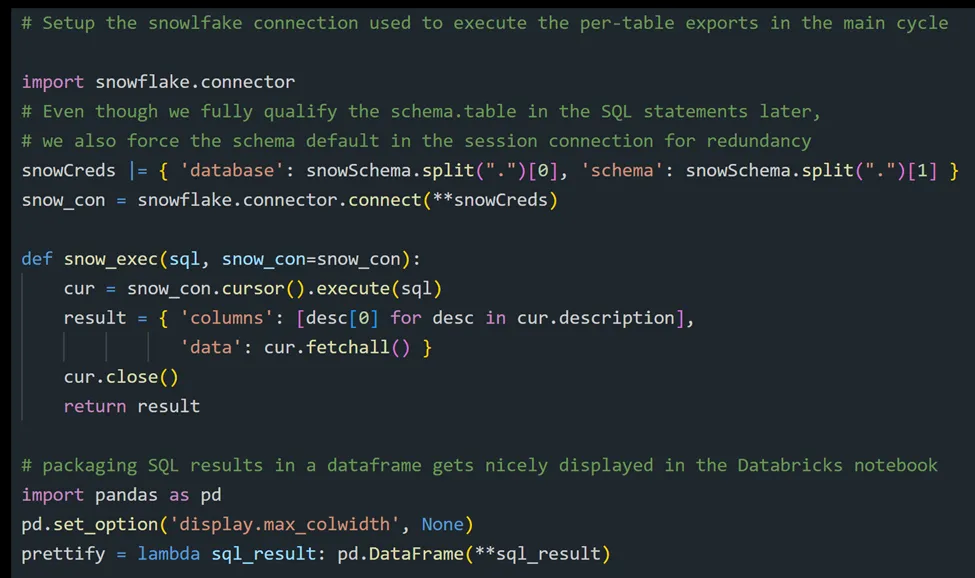
Step 2 — Export Snowflake data to Parquet
We’re ready to work on our first target: transferring 4.75m rows of diagnosis data from the Snowflake table DIAGNOSIS_ICD to Databricks. First, we must identify the ADLS container to Snowflake as a “stage” area…
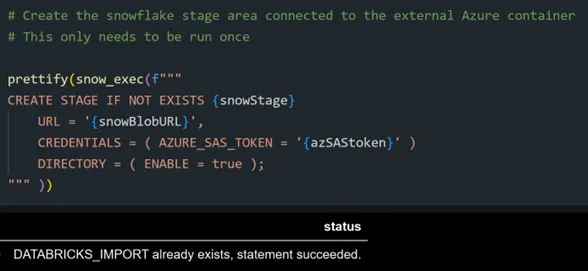
… And because this was already done earlier, we get the “already exists” result.
Our logic uses the variable tableName to identify whatever table we want to migrate. We’re going to start with the DIAGNOSIS_ICD table…
![]()
We execute a COPY INTO to generate the collection of Parquet objects in the stage area…
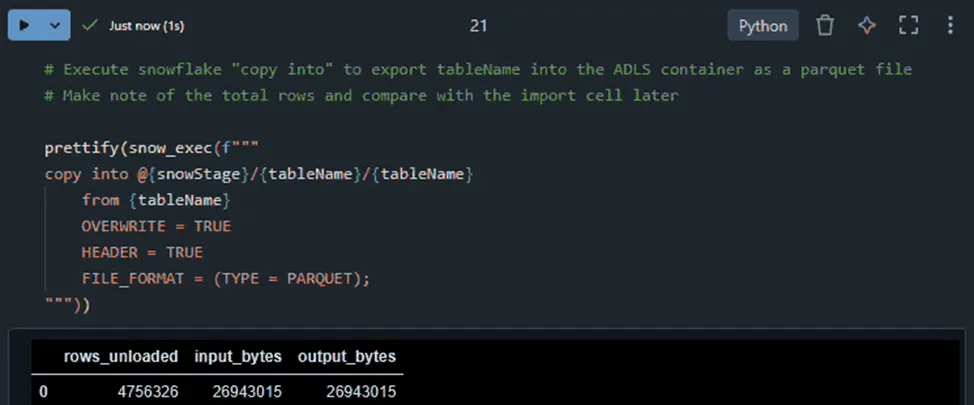
The Snowflake statement converted the table into snappy compressed Parquet objects, each about 25MB in size, under a folder with the same name as the table. We query ADLS to observe the objects…
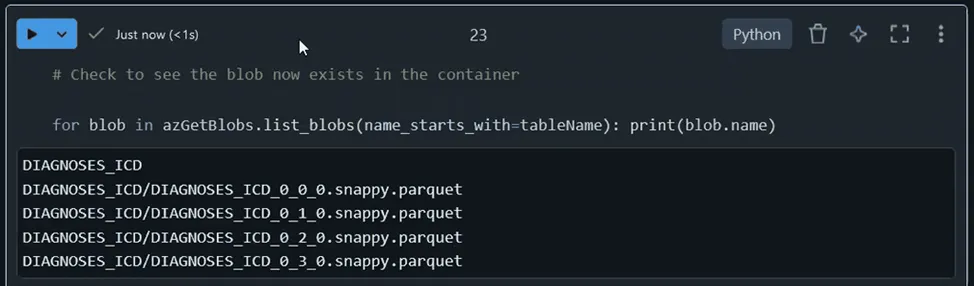
Step 3 — Import Parquet data to Databricks
These objects can now be loaded into Databricks. First, we create Spark keys equivalent to tableName to be used in the upcoming SQL magic cell…
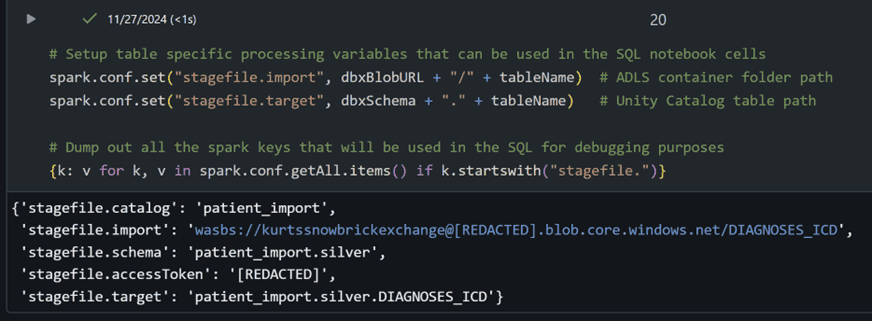
Notice the target table patient_import.silver.DIAGNOSES_ICD is described using the 3-level namespace of Databricks Unity Catalog (catalog > schema > table). This requires that the catalog and schema must already exist…

The load process is similar to the earlier export process, but in reverse…
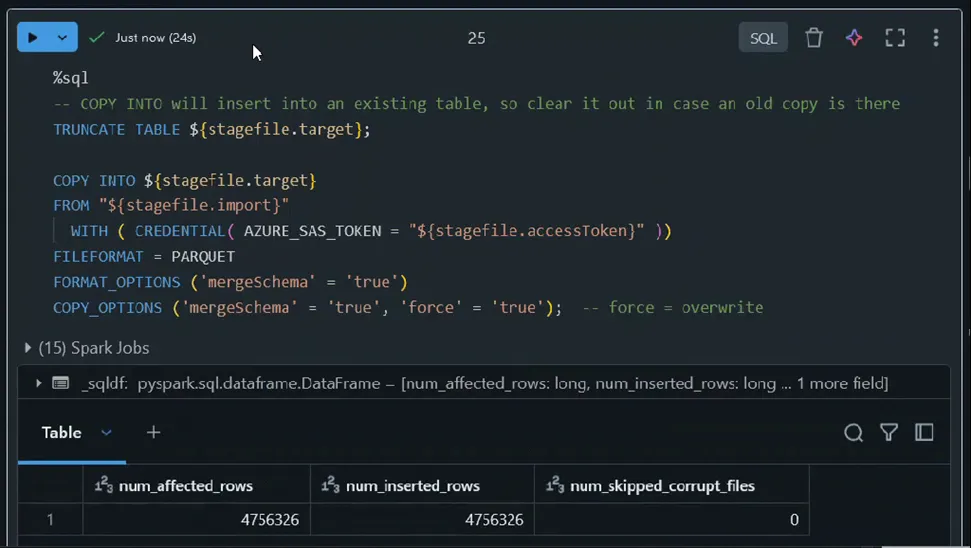
Notice the row count matches the earlier export count. The data is immediately managed through Unity Catalog, which provides a helpful “starter” glossary definition, demonstrating how effectively GenAI integrates into the user workflow…
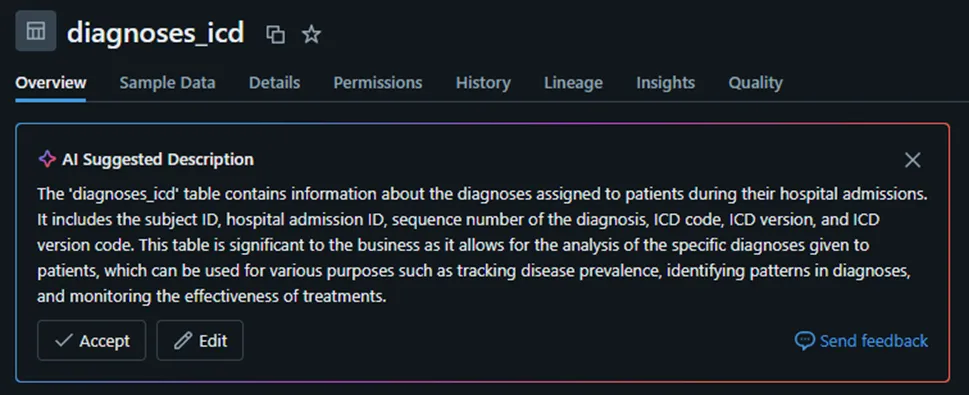
Step 4 — Validation
We’ve already noted that the row counts match. We examine the metadata equivalence…
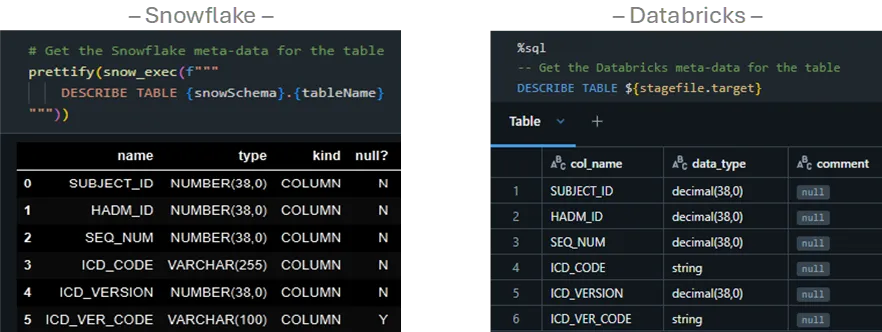
We test the cardinality of the 4.75 million rows by checking the counts of the distinct SUBJECT_ID …
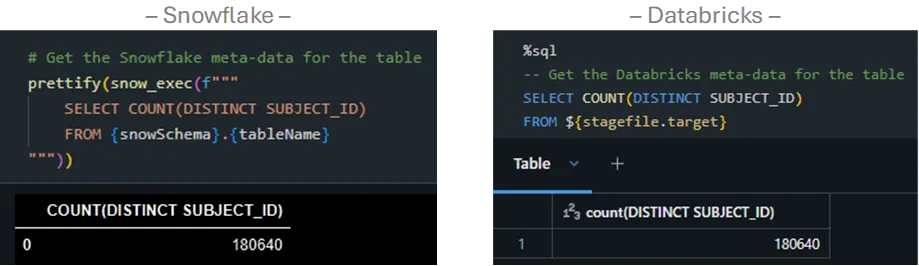
…And Repeat
The same process is repeated for the remaining schema tables. Once finished, a business query demonstrates accurate relationships, cardinality, consistency of field values, and their correct filtering and aggregation handling.
We’ll jump over to the Databricks SQL Query tool and run the statement below examining pneumonia admissions DRGs…
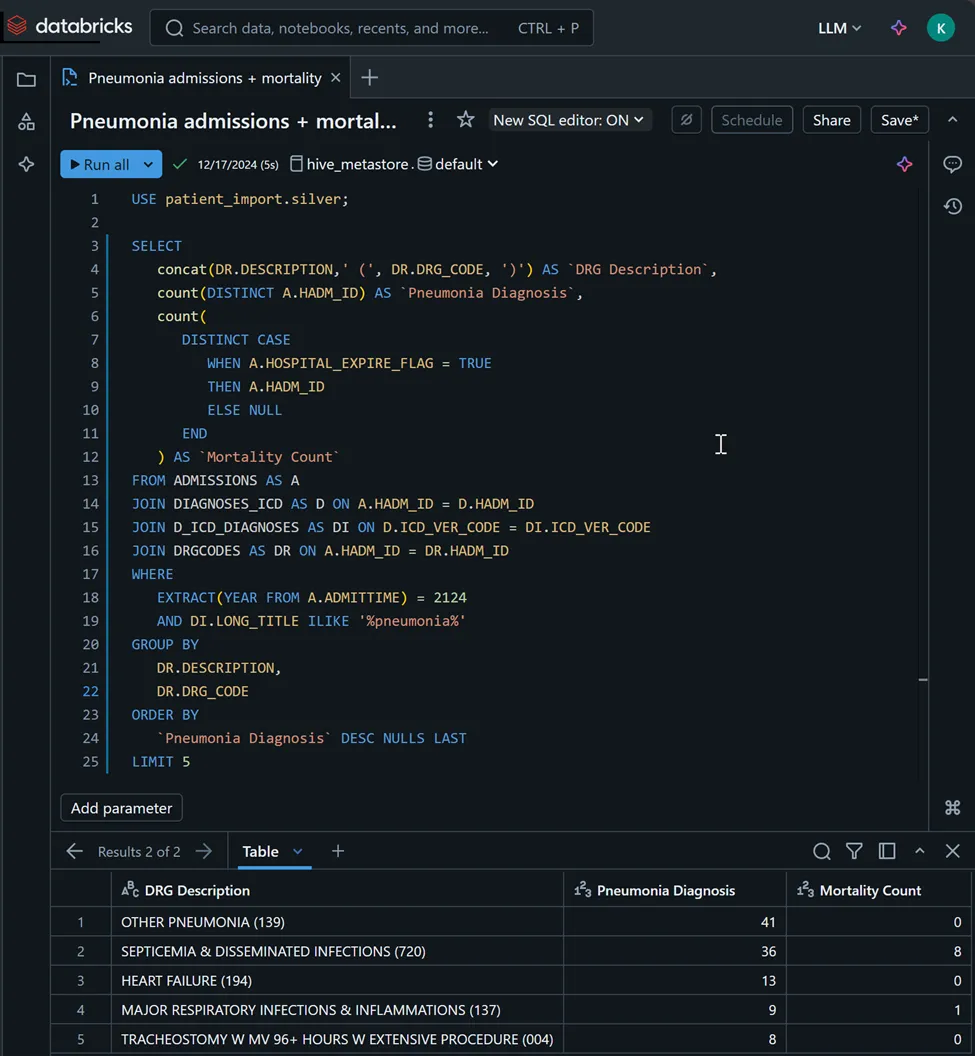
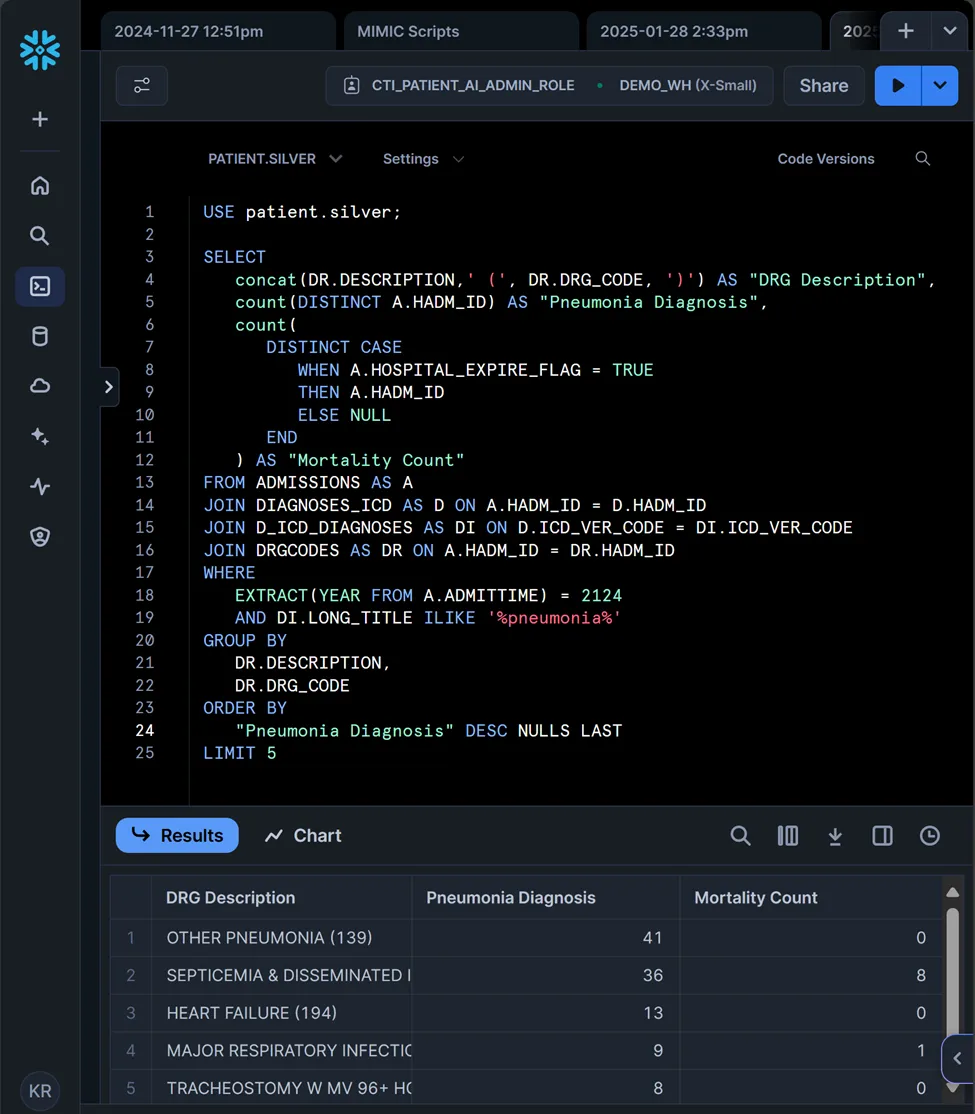
… and running the same query in Snowflake produces identical results…
Conclusion
We have shown the mechanics of transferring data from Snowflake to Databricks are not complicated; large datasets can be relocated to the Databricks platform for initial experimentation within days.
Keep in mind that the methods presented are meant to demonstrate concepts; they lack robust error handling and need deeper data validation and automation. Finally, this guide focuses on data migration; transferring SQL workloads is a more complex endeavor, which we touch upon in our whitepaper.
References
The Databricks Juptyer Notebook is available here
or here for importing into your Databricks environment
For more information, contact kurtr@ctidata.com